
「一様乱数の平均値を正規乱数として代用する」という話をゆるふわ統計的に検証する
「一様乱数を足し合わせて平均値をとった値は正規分布っぽくなるよ」というツイートを見かけて、「それって統計的にどうなんだろう?」という疑問が湧いたので検証してみました。
はじめに
昨日・一昨日ぐらいに Twitter 上でちょっとした話題になっていた
アニメーションの監修で、「 Random();の代わりに、(Random()+Random()+Rrandom()+Random()+Random())/5.0f; を使うと、動きにコクが出る」と言ったら、ピュアオーディオ扱いされるのですが・・・これは根拠のあるアルゴです。
— 深津 貴之 (@fladdict) 2016年11月3日
というツイートに関連して、「一様乱数の平均値を正規乱数として代用する」的なツイートをちらほら見かけて気になっていたので、統計的に検証してみましたよ、というブログエントリです (このツイート自体に対して揶揄するつもりはなく、また「コク」云々について物申す気も一切ないことをご承知おきください)。
なお上記ツイートに関連する話題は、乱数にコクを出す方法について の Togetter をご覧いただくのがいいかと思います。
中心極限定理と一様乱数からの正規乱数の生成
まず、「一様乱数の平均値を正規乱数として代用する」ことの根拠としている重要な定理、中心極限定理 について復習しておきます。
Wikipedia における中心極限定理の説明 をもとに、中心極限定理を簡単に説明すると、
平均 $\mu$、分散 $\sigma^2$ の分布から生成された $n$ 個の乱数の合計値を $S_n$ とすると、 $\frac{S_n - n \mu}{\sqrt{n} \sigma}$ は平均 0、分散 1 の正規分布 (標準正規分布) $N(0, 1)$ に近似的に従う
となります。
一方で今回のツイートにあるように、母数 $a=0, \ b=1$ の一様分布 (平均 $1/2$, 分散 $1/12$) から生成された $n$ 個の一様乱数の平均値 $S_n / n$ は、平均 $1/2$、分散 $1 / 12n$ の正規分布 $N(1/2, 1 / 12n)$ に近似的に従うことになります。
このため、例えば Java でいうところの java.util.Random#nextGaussian() 相当の正規乱数 ($\sim N(0, 1)$) が欲しい場合は、単に $n$ 個の乱数の平均を取るのではなく、 $\frac{S_n - n/2}{\sqrt{n/12}}$ とする必要があります。
加えて、近似的に得られる正規乱数の区間が $[\frac{-n/2}{\sqrt{n/12}}, \frac{n/2}{\sqrt{n/12}}]$ に限定されてしまうことにも注意が必要です。
ひとまずこの「一様乱数の平均値を正規乱数として代用する」方法を、$N(0,1)$ の正規分布に従う形で Java で実装してみると、以下のようになります。
import java.util.Random;
public class ApproximateGaussianRNG {
private final int N;
private final double N_HALF;
private final double M;
public PseudoGaussianRNG(int n) {
N = n;
N_HALF = 0.5 * N;
M = Math.sqrt(N / 12.0);
}
public double generate(Random random) {
double t = 0.0;
for (int i = 0; i < N; i++) {
t += random.nextDouble();
}
return (t - N_HALF) / M;
}
}
正規乱数としての品質を検証する
続いて、この方法で生成する正規乱数の品質を 「コク」といった定性的なものではなく 統計を用いて定量的に検証してみましょう。
ある確率分布に従った乱数を生成してくれる乱数生成器に対して、統計的にその品質を測るには、「まず確率分布を面積の等しい複数個の領域に分割し、続いて乱数生成器によって大量に生成した乱数がそれぞれの領域において何個含まれるかを数え上げ、最後にカイ二乗検定で検定する」といった方法をとります。これにより、 $\chi^2$ 値や p 値といった数値でその乱数生成器の品質を測定できるようになります。
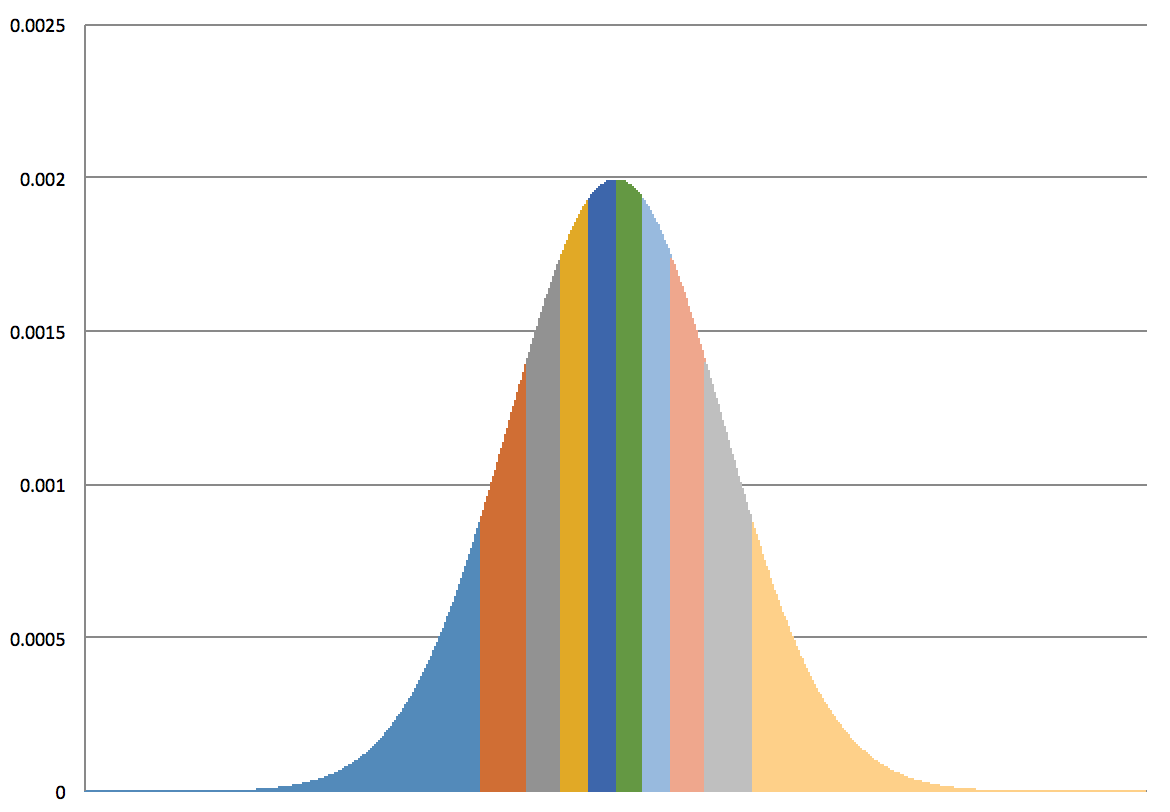
具体的には、正規分布であれば以下の図のように 10 個の領域に分割し、$n$ 個の正規乱数を生成したとして、それぞれの領域に含まれる乱数の個数の期待値 $n/10$ 個と実際の個数がどれくらいずれているのかをカイ二乗検定で判断することになります。
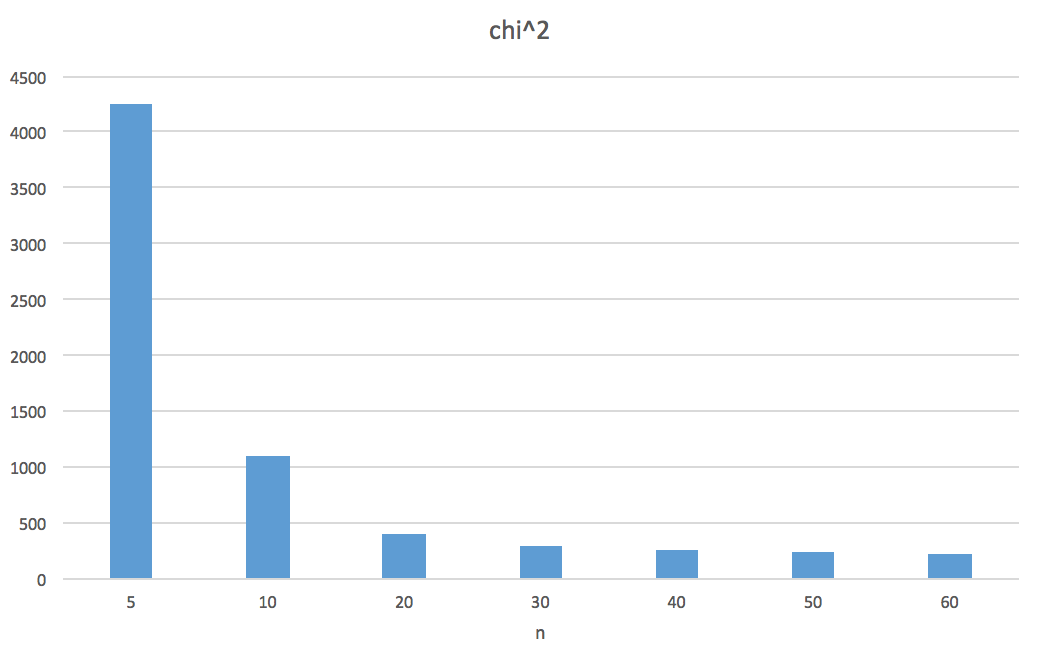
この検証方法に習って、領域の数を 200 個、生成する乱数を 200 万個にして、今回の「一様乱数の平均値を正規乱数として代用する」方法を検証してみると、正規乱数の生成方法として一般的に知られている ボックス=ミュラー法 と同程度の統計的な品質を達成するには、$n=60$、つまり 60 個の一様乱数の生成が必要になることが分かりました (検証に用いた Java のコードは こちら)。
以下は $n$ を 5, 10, 20, 30, 40 50, 60 と変化させたときの $\chi^2$ 値の変化を表す図です。これを見ると明らかなように、$n=5$ で正規乱数の代わりに用いようとするのは統計的には厳しいですね。
速度性能を評価する
最後に速度性能の観点で評価をしてみましょう。
「一様乱数の平均値を正規乱数として代用する」方法は上述したとおり、統計的な品質面でデメリットがあることがわかりましたが、その一方で実装の単純さゆえ、正規乱数としての品質を犠牲にしつつもより高速な正規乱数の生成器が必要な場面での活用が見込まれます。それでは実際に、一般的なボックス=ミュラー法による正規分布からの乱数生成器と比較して、速度性能的にどれくらい優れているのかを測定してみましょう。
今回は引き続き Java で ベンチマークプログラム を用意し、jmh で 1 秒あたりの乱数生成個数 (ops/sec) を測定しました。結果は以下のとおりです。
Benchmark Mode Cnt Score Error Units
GaussianBenchmark.approximate thrpt 100 64373100.278 ± 476861.684 ops/s
GaussianBenchmark.threadLocalRandom thrpt 100 22672233.337 ± 157199.847 ops/s
java.util.concurrent.ThreadLocalRandom クラスの ThreadLocalRandom#nextGaussian() メソッドは、ボックス=ミュラー法を用いて正規乱数を生成しています。このメソッドの 1 秒あたりの乱数生成個数は約 2,267 万個です。一方で $n=5$ での一様乱数をもとにした乱数生成器 (approximate) は 6,437 万個と、その性能比は 2.84 倍となります。
この結果より、「一様乱数の平均値を正規乱数として代用する」方法にも速度性能面で価値がある… と判断したいところではありますが、でも世の中に存在する正規乱数の生成方法はボックス=ミュラー法だけではありません。より高速な正規乱数の生成方法に Ziggurat 法 が存在します。この Ziggurat 法を加えて速度性能を評価した結果は以下のとおりです。
Benchmark Mode Cnt Score Error Units
GaussianBenchmark.approximate thrpt 100 64373100.278 ± 476861.684 ops/s
GaussianBenchmark.threadLocalRandom thrpt 100 22672233.337 ± 157199.847 ops/s
GaussianBenchmark.ziggurat thrpt 100 67887363.802 ± 783005.185 ops/s
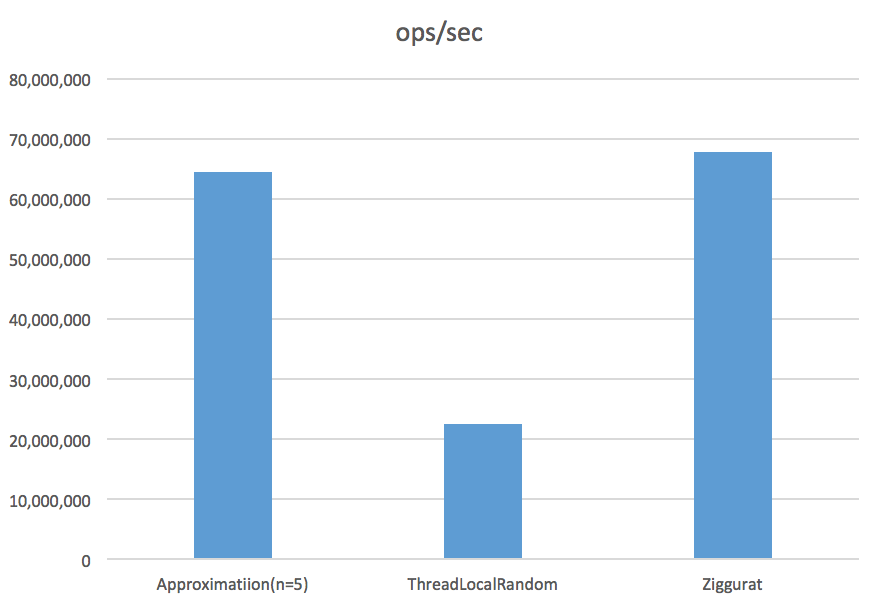
おおっと、Ziggurat 法が速度性能的に一番良いようですね… こうなると、正規乱数を生成する目的で「一様乱数の平均値を正規乱数として代用する」方法を採用する理由は残念ながらないと言えそうです。
まとめ
- 「$[0,1]$ の一様乱数の平均値」は $N(1/2, 1 / 12n)$ の正規分布に近似することと、区間が $[\frac{-n/2}{\sqrt{n/12}}, \frac{n/2}{\sqrt{n/12}}]$ となることに注意が必要だよ
- 正規乱数の乱数生成器として、「一様乱数の平均値を正規乱数として代用する」方法を用いるのはまったくおすすめできないよ
- 統計的に見て品質は悪いし、速度性能も Ziggurat 法と比較して負けてる
- ただし、「一様乱数でもなく正規乱数でもなく、でもちょっと正規分布に従っているっぽい乱数」を生成する目的で使うのはいいと思うよ
- これが多分「コク」に通ずるものなのだろう
今回の検証に用いたプログラムはすべて以下の git リポジトリに納めています。