
Java で最速の乱数生成器を目指す: (2) 指数分布に従う乱数
fast-rng に実装した 指数分布 (exponential distribution) に従う乱数生成器についてのメモです。
はじめに
前回 のブログエントリでは、正規分布に従う乱数生成器を実装し、その速度検証をしました。 今回は「指数分布に従う乱数」の実装を目指します。
指数分布は例えば、コールセンターで次々に客から電話がかかってくるような状況において、ある電話がかかってきてから次の電話がかかってくるまでの時間間隔など、確率的に生じる事象の時間間隔をモデル化するのに適した確率分布です。指数分布の確率密度関数は $x > 0$ のときに $f(x) = \frac{1}{\theta} e^{-x/\theta}$ で表され ($\theta$ はスケールパラメータで $\theta > 0$)、下図のようになります。
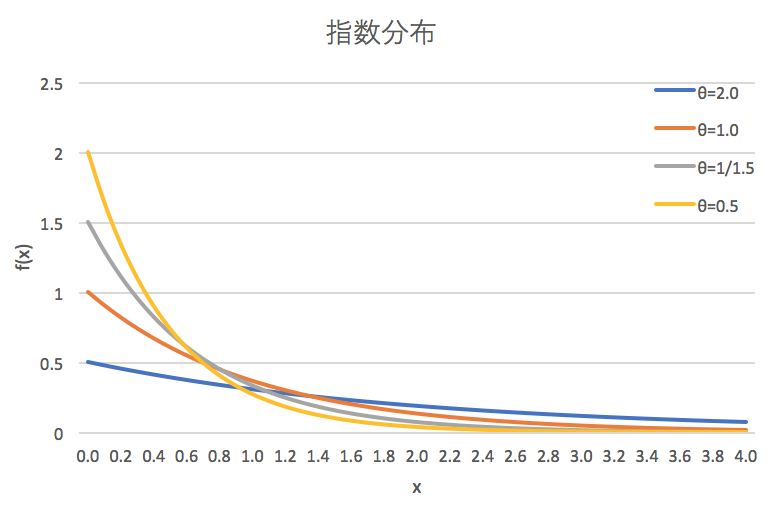
一様乱数や正規乱数と比べると、指数分布に従う乱数の利用機会はさほど多くない (というか、かなり少ない) かと思われますが、後々のガンマ分布の乱数生成を見据え 1、できる限り高速な実装を用意してみます。
なお今回の指数分布に従う乱数生成器の実装においても「計算機シミュレーションのための確率分布乱数生成法」の書籍より多くを参考にさせていただいております。
「指数分布に従う乱数」を生成する方法
書籍「計算機シミュレーションのための確率分布乱数生成法」では、逆関数法、Odd-Even 法、Ziggurat 法の 3 つのアルゴリズムが紹介されています。このうち Odd-Even 法については、乱数生成器の内部で状態を持つ必要があり、マルチスレッド対応が面倒であるのと、書籍に掲載されているパフォーマンス比較でも特別性能がよい、というわけでもないので、今回の速度性能の検証対象からは除外しています。
また、R の rexp() 関数や Apache Commons Math の ExponentialDistribution#sample() では、Ahrens, Dieter らのアルゴリズム SA が採用されています。こちらはベースラインの一つとして、速度性能の検証対象に含めています。
以下、各アルゴリズムについて簡単に説明します。
逆関数法
指数分布の累積分布関数 $F(X) = 1 - e^{-x/\theta}$ の逆関数 $F^{-1}(u) = - \theta \log(1 - u)$ を用いて、指数分布に従う乱数を生成する方法です。具体的には、$[0, 1)$ の区間の一様乱数 $u$ を生成して $F^{-1}(u)$ を出力の乱数とします ($1-u$ とすることで、一様乱数の区間を $(0, 1]$ とし、$\log 0$ となってしまうケースを回避しています)。
この方法は複雑な実装を一切必要とせず、java.lang.Math クラスなどの log() メソッドだけを利用すれば簡単に実現できるのがメリットと言えます。デメリットは、乱数を生成する度に必ず log() を呼び出さなければならないことです。
Java において、log() の処理は数学関数の実装の中でもかなり重い (遅い) 部類になります。そのため、速度性能を追い求める場合はできる限り log() の呼び出しを回避した実装にすることが好まれます。
なお log() に限った話ではありませんが、JDK 標準の数学関数実装はその多くが速度的に効率がよいとは言えず、Commons Math や Jafama などの代替実装の方が高効率となることがあります。
この辺の話は、以前とある勉強会で話したときの発表資料「Java の数学関数を計算速度的に極めたい」をご参照ください。
また、log(1 - u) を呼び出しを log1p(-u) の呼び出しに置き換えることで高速化を図る方法もあります。JDK および Commons Math の log1p() とは違い、Jafama のそれは log() よりも高速であるため、log1p() に置き換えだけで逆関数法の速度性能を向上させることが期待できます。
Ziggurat 法
正規乱数の実装で利用した Ziggurat アルゴリズムは、指数分布に従う乱数生成にも適用できます。
確率分布を面積の等しい n - 1 個の長方形と裾の部分の合計 n 個の領域に分ける、といった手順は正規分布のときとまったく同じで、異なるのは確率密度関数 $f(x)$ や $r,v$ の値、そして確率分布の裾の部分からの乱数生成方法ぐらい、です。
なお、先の書籍において、裾の部分における乱数は $F^{-1}_{tail} (u) = \theta (r - \log(1-u))$ として逆関数法的に生成していましたが、英語 Wikipedia の Ziggurat algorithm のページ に記載されているとおり、指数分布の乱数生成関数を再帰的に呼び出すことで裾の部分の乱数生成を実現する方法もあります。Ziggurat 法による乱数生成が十分に高速であれば、再帰呼び出しにすることで log() を呼び出すよりも高速な乱数生成が期待できるでしょう。
アルゴリズム SA
アルゴリズムの詳細は論文 Computer methods for sampling from the exponential and normal distributions や R の rexp() の 実装、Commons Math での 実装 に譲るとして、このアルゴリズムの特徴は、乱数生成の処理に数学関数の呼び出しが含まれないことにあるでしょう。逆関数法のところで述べたとおり、log() の呼び出しを排除することで高速な乱数生成が見込まれます。
パフォーマンス検証
さて、上記にて説明した 3 つのアルゴリズムについて Java で実装し、その性能を比較してみましょう。 今回の比較対象は次の 7 つになります。
- 逆関数法 (log)
-log(1 - random.nextDouble()) * thetaとして乱数を生成しますlog()の実装は、Commons Math のFastMath.log()を利用します
- 逆関数法 (log1p)
-log1p(-random.nextDouble()) * thetaとして乱数を生成しますlog1p()の実装は、Jafama のFastMath.log1p()を利用します
- Ziggurat (3.43)
- 「計算機シミュレーションのための確率分布乱数生成法」のアルゴリズム 3.43 の実装です
- 一様乱数がビット独立であることを仮定した場合に利用できるアルゴリズムです
- 確率分布の裾の部分の乱数生成では、逆関数法を利用します
- Ziggurat (3.43 & recursive)
- Ziggurat (3.43) の裾の部分の乱数生成を再帰に置き換えた実装です
- Ziggurat (3.44)
- 同書籍のアルゴリズム 3.44 の実装です
- 一様乱数のビット独立性を仮定しないアルゴリズムです
- 確率分布の裾の部分の乱数生成では、逆関数法を利用します
- Ziggurat (3.44 & recursive)
- Ziggurat (3.44) の裾の部分の乱数生成を再帰に置き換えた実装です
- アルゴリズム SA
- このアルゴリズムのみ自前実装はせず、Commons Math の実装 (
ExponentialDistribution#sample()) を利用することにします
- このアルゴリズムのみ自前実装はせず、Commons Math の実装 (
上記のいずれも、一様乱数の生成には ThreadLocalRandom を利用します。また、jmh によるパフォーマンス測定ではスレッド数を 1 とします。
測定結果は以下のとおりです。
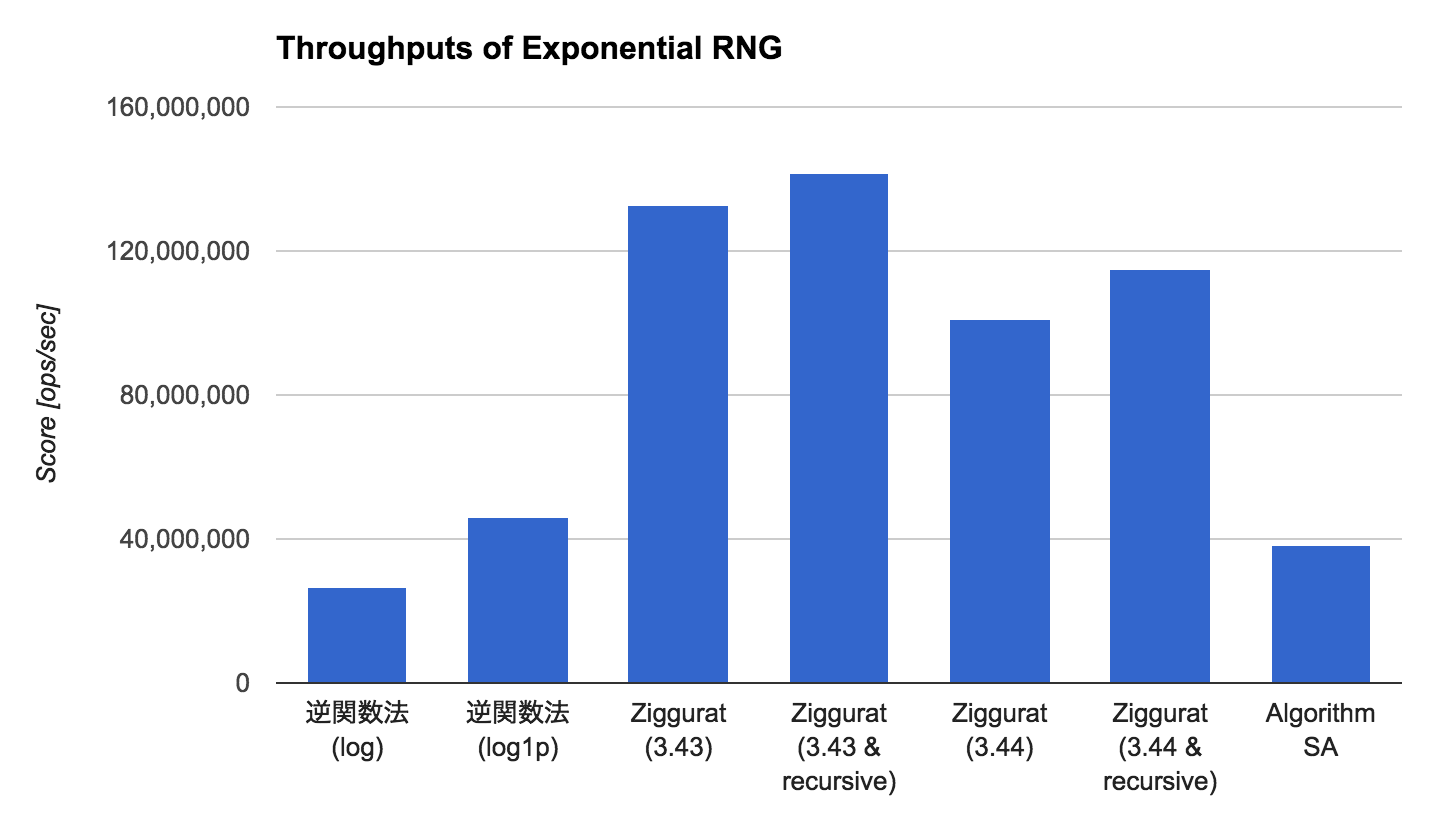
ご覧のとおり、正規乱数のときと同じく Ziggurat 法の結果が他のアルゴリズムを圧倒する結果となりました。特に、裾の部分での乱数生成を逆関数法ではなく再帰に置き換えることで、よりよい速度効率が追求できることがわかります。
逆関数法においては、log() より log1p() を用いた方が速度効率がよいことがわかります。アルゴリズム SA は、その実装から察するに、処理自体は単純であるものの、指数分布に従う乱数を一つ生成する際に多数の一様乱数 (最低でも 3 つ) を必要とするがために、速度性能が伸びないのではないかと思われます。
Commons Math による既存実装が存在するアルゴリズム SA をベースラインとすると、Ziggurat (3.43 & recursive) は約 3.7 倍、Ziggurat (3.44 & recursive) でも約 3.0 倍の速度性能を達成することができています。
まとめ
今回は指数分布に従う乱数生成器として Ziggurat アルゴリズムによる実装を行い、Commons Math の実装 (ExponentialDistribution#sample()) をベースラインとして 3 倍以上の速度性能を達成することができました。
今回の指数分布に従う乱数生成器は fast-rng 0.1.3 として公開しています。
-
形状母数を 1 としたときのガンマ分布が指数分布となる ことを利用したガンマ分布の乱数生成を想定しています。 ↩