
Java で POJO を JSON シリアライズして gzip 圧縮するまでを高速に処理したい
Jackson や Java における zlib 関連クラス、zlib そのものの内部実装を把握しながらスループットの最適化を試みるお話です。
はじめに
Java で書かれた Web アプリケーションにおいて、HTTP リクエストに応じて内容が大いに異なり、かつかなり大きな (具体的には数メガバイトの) JSON 文字列を HTTP レスポンスとして返さざるを得ない状況に遭遇したとします。 このとき、アウトバウンド・トラフィック量を削減する目的で Java のレイヤで gzip 圧縮しようとした場合1 に、どのような実装をすれば POJO の JSON シリアライズから gzip 圧縮までの処理のスループットを上げられるかを検証してみました。
基本構成
今回の検証では、POJO の JSON シリアライズに Jackson (jackson-databind) を、gzip 圧縮には Java クラスライブラリで実装されている GZIPOutputStream クラスを利用することとします。
Jackson の ObjectMapper クラスには、POJO を JSON にシリアライズするためのメソッドがいくつか備わっています。今回のケースでは、JSON シリアライズ結果を (余計な変換処理などの手間なく) 直接 OutputStream オブジェクトに出力できる ObjectMapper#writeValue(OutputStream, Object) メソッドを選択することにします (参考: Jackson でハイパフォーマンスな JSON 処理を追求する)。
ここで、POJO を JSON シリアライズして gzip 圧縮するまでの具体的な処理をするベースライン実装は以下のようになります。
// この ObjectMapper のオブジェクトは実際にはクラス変数などで保持し、複数スレッドで共有して利用する
ObjectMapper mapper = new ObjectMapper();
try (ByteArrayOutputStream baos = new ByteArrayOutputStream();
GZIPOutputStream gzipOut = new GZIPOutputStream(baos)) {
mapper.writeValue(gzipOut, objects);
gzipOut.close();
byte[] gzippedBytes = baos.toByteArray();
int length = gzippedBytes.length;
// Content-Length を設定しつつ gzippedBytes をレスポンスとして返す実装をする
}
以降は、このベースライン実装をパフォーマンス的に改善する試みを一つ一つ挙げて行きます。
Gzip (zlib) の圧縮レベルを調整する
Gzip に限ったことではありませんが、一般的にデータ圧縮アルゴリズムは圧縮率を高めるその目的のために CPU-intensive な処理になる傾向があります。それゆえに、今回の一連の処理のスループットを高めるためにまずすべきことは、CPU 負荷が低く抑えられるような圧縮パラメータを選択する ことになります。ただし、圧縮処理における CPU 負荷と実際に得られる圧縮率はトレードオフの関係にあるため、CPU 負荷を下げようとする試みは圧縮率が犠牲になることに注意が必要です。
さて Java における gzip 圧縮処理の実装には zlib が利用されています が、この zlib が提供する deflate アルゴリズム 実装には 1 から 9 までの 9 段階の圧縮レベルが制御可能なパラメータとして存在します。この圧縮レベルは、その具体的なレベルごとに good_length, max_lazy, nice_length, max_chain, compress_func の 5 つの内部パラメータを制御しています2。
deflate アルゴリズムは LZ77 と Huffman 符号を組み合わせたアルゴリズムであり、上記の 5 つのパラメータはこのうち前者を実現する LZ parsing の振る舞いを制御します。参考までに、それぞれのパラメータの制御内容は以下に示すとおりです。
- good_length
- Lazy matching と呼ばれる、より長い一致文字列を探索する仕組みを制御するパラメータの一つ
- 一文字前の位置で見つかった一致文字列の長さがこのパラメータの値以上の場合に、ハッシュチェーンをたどる最大回数が 1/4 になる (厳密には、パラメータ max_chain が 1/4 された値が使われる)
- max_lazy
- これも lazy matching の振る舞いを制御するパラメータの一つ
- 一文字前の一致文字列の長さがこの値を下回る場合にのみ、lazy matching が行われる
- nice_length
- ハッシュテーブルを用いて一致文字列を探す処理を制御するパラメータの一つ
- 現時点で見つかっている一致文字列の長さがこのパラメータの値以上となった場合に、ハッシュチェーンをたどる処理を抜ける
- max_chain
- こちらも、ハッシュテーブルを用いて一致文字列を探す処理を制御するパラメータの一で、ハッシュチェーンをたどる最大回数を表す
- 前述したように、good_length のパラメータによって実際に使われる max_chain の値がその時々で変化しうる
- compress_func
- LZ parsing の処理に
deflate_slow()とdeflate_fast()のどちらの関数を利用するのかを表すパラメータ - それぞれの関数の違いは、lazy matching 実装の有無と、ハッシュテーブルに一致文字列の部分文字列も登録するか否かにある
- LZ parsing の処理に
Java には、この deflate アルゴリズムの圧縮レベルを制御する手段として Deflater#setLevel() メソッドが提供されています。しかし、この Deflater クラスを利用して gzip 圧縮を実現している GZIPOutputStream クラスには、同メソッドを呼び出して圧縮レベルを設定する手段が提供されていません。そのため、GZIPOutputStream で圧縮レベルを設定するには、例えば以下のように GZIPOutputStream を継承するクラスを用意し、protected なフィールド def を通じて圧縮レベルを設定 すればよいでしょう。
package me.k11i.benchmark;
import java.io.*;
import java.util.zip.GZIPOutputStream;
public class GZIPOutputStreamWithCompressionLevel extends GZIPOutputStream {
public GZIPOutputStreamWithCompressionLevel(int level, OutputStream out) throws IOException {
super(out);
def.setLevel(level);
}
public GZIPOutputStreamWithCompressionLevel(int level, OutputStream out, int size) throws IOException {
super(out, size);
def.setLevel(level);
}
}
Deflater の出力バッファを調整する
zlib には、データ圧縮をストリーム的に処理するための API である deflate() 関数が実装されています。Java の Deflater クラスも、ネイティブメソッド内でこのストリーム API を利用して deflate 圧縮を実現しています。
この zlib のストリーム API は、圧縮しようとしている入力データをストリーム API に提供するための 入力バッファ、および zlib によって圧縮された出力データを受け取るための 出力バッファ それぞれをライブラリ利用者側自身が確保・管理する必要があります。deflate() 関数はできる限り入力バッファ上のデータを処理し、また出力バッファを圧縮済みデータで満たすように振る舞います。そのため、Java においてパフォーマンスのボトルネックになりがちなネイティブメソッドの呼び出し回数を減らすためにも、十分な大きさの入出力バッファを用意することが肝心です。
Java においては、入力バッファは GZIPOutputStream#write(byte[], int, int) で指定された byte 配列が入力バッファとしてそのまま使われます。一方で出力バッファには GZIPOutputStream の親クラスである DeflaterOutputStream クラスが管理するバッファが使われ、そのバッファサイズは コンストラクタパラメータの size で制御 できます。
Jackson と GZIPOutputStream 間のバッファリングを検討する
上述したように、Deflater クラスの入出力に関わるバッファを適切に調整することで zlib の deflate() 関数に関わるネイティブメソッドの呼び出し回数を削減する効果が期待できるわけですが、今回の構成において入力バッファは ObjectMapper#writeValue(OutputStream, Object) メソッドの実装に依存してそのバッファサイズが決定されることになります。
従って、まずは同メソッドおよび関連機能の実装を紐解いて理解を深めることから始めます。
ObjectMapper#writeValue(OutputStream, Object) の処理を IDE やそのデバッガに頼りつつ追っていくと、JsonFactory クラスの _createUTF8Generator(OutputStream, IOContext) メソッド経由で UTF8JsonGenerator クラスのオブジェクトが生成されることがわかります。この UTF8JsonGenerator が POJO をシリアライズし、結果を OutputStream#write(byte[], int, int) で書き出すまでの一連の処理を担当しています。
また UTF8JsonGenerator クラスのコンストラクタでは、 IOContext オブジェクトおよび BufferRecycler オブジェクトを経由して 8,000 バイトの内部バッファを用意しています。
UTF8JsonGenerator における JSON シリアライズの処理中は、このバッファにシリアライズ結果が逐次書き出されていきます。
そして、バッファの空きに余裕がなくなって UTF8JsonGenerator#_flushBuffer() メソッドが呼ばれることで、実際に OutputStream にシリアライズ結果のバイト列が書き出されるわけです。
すなわち、この UTF8JsonGenerator クラスの内部バッファ (8,000 バイト) が最終的に deflate() 関数に入力バッファとして渡される ことになります。
なおこの内部バッファは、ObjectMapper#writeValue(OutputStream, Object) メソッドを呼び出すたびにオブジェクト生成される わけではありません。
JsonFactory クラスにおいて BufferedRecycler オブジェクトを取得する 際に利用している BufferRecyclers クラスの実装を見て明らかなように、ThreadLocal および SoftReference オブジェクトに包まれる形で BufferRecycler オブジェクトの単位でキャッシュされています。
そのため、再利用されうるスレッドで ObjectMapper#writeValue(OutputStream, Object) を実行する限りにおいては、内部バッファ生成に伴うオーバーヘッドがほとんど発生しないことが期待できます。
この内部バッファをキャッシュする・しないの挙動は、JsonFactory.Feature.USE_THREAD_LOCAL_FOR_BUFFER_RECYCLING の設定で切り替えることができます (デフォルトは ON)。
さてこの JSON シリアライズ用の出力バッファなのですが、このバッファサイズを自由に設定できるかというと、そのような機構は現時点のバージョン 2.9.9 では残念ながら提供されていません。なので、この内部の出力バッファのサイズを調整して (大きくして) スループットを向上する… といった手段をとることは容易にはできません。そのため、若干余計には思われるものの、Deflater クラスのネイティブメソッドの呼び出し回数を減らす観点で考えた場合、ObjectMapper と GZIPOutputStream の間にあえて BufferedOutputStream オブジェクトを挟む などの手段が考えられるでしょう。
Jackson/ObjectMapper による POJO のシリアライズを afterburner で加速する
ここまでは圧縮処理周りのパフォーマンス改善について見てきましたが、POJO のシリアライズを高速化する手段も考えてみましょう。
Jackson には、それぞれの POJO に適した個別のシリアライザ実装をバイトコード生成で動的に作り出せるようになる Afterburner (jackson-module-afterburner) というモジュールが提供されています。
このモジュールの使い方はとても簡単で、以下のように ObjectMapper#registerModule(Module) メソッドで AfterburnerModule クラスのオブジェクトを設定するだけです。
ObjectMapper mapper = new ObjectMapper().registerModule(new AfterburnerModule());
ベンチマーク
ここまで見てきたパフォーマンス改善の試みが実際に効果があるか否かを、ベンチマークを測定して評価してみます。 なお、ベンチマーク測定に用いたコードは github.com/komiya-atsushi/java-playground のリポジトリに置いてあります。
今回のベンチマークは以下の条件で測定します。
- Json Generator を用いてダミーの JSON データを 作成する
- ベンチマークを測定開始する前にこの JSON データをデシリアライズして、Java のヒープ上に POJO の状態で保持しておく
- このダミーデータの POJO そのもの (POJO x1) と、それをさらに 10 倍にコピーして増やした POJO (POJO x10) の 2 つのデータセットを評価に用いる
- 各種パフォーマンス改善の試みの組み合わせすべてについて、スループット (ops/s) を測定する
DeflaterOutputStreamの出力バッファ、および Jackson とGZIPOutputStreamの間に挟むBufferedOutputStreamによる (zlib からみたときの) 入力バッファのサイズはいずれも 64KB 固定とする- 圧縮レベルはデフォルト (6) と速度重視 (1) を比較する
- なお、圧縮レベルの違いはスループットに与える影響が大きいので、それ以外の試みと分けて評価する
- JMH でベンチマーク測定する際のスレッド数は 50 に設定する
JSON シリアライズされたデータセットのサイズは以下のとおりです (カッコ内の % は 100 * 圧縮後サイズ / 圧縮前サイズ で算出した圧縮率)。
| - | POJO x1 | POJO x10 |
|---|---|---|
| Raw JSON | 114KB | 1,139KB |
| Gzip 圧縮 (レベル: 6) | 34KB (30.0%) | 331KB (29.1%) |
| Gzip 圧縮 (レベル: 1) | 40KB (35.3%) | 395KB (34.7%) |
今回のベンチマークに用いるダミーデータでは、圧縮レベルを 1 にした場合の圧縮率とデフォルトの圧縮レベル (6) のそれとで、5 ポイントの損失が生じています。 この 5 ポイントの圧縮率の損失が大きいと見るか小さいと見るかはケースによるでしょうが、今回のベンチマークでは許容できる程度の損失とみなします。
Gzip の圧縮レベルによる影響を評価する
まずは、圧縮レベルをデフォルトの 6 から速度重視の 1 に変更した場合のスループットについて見ていきます。結果は以下のチャートのとおりです。
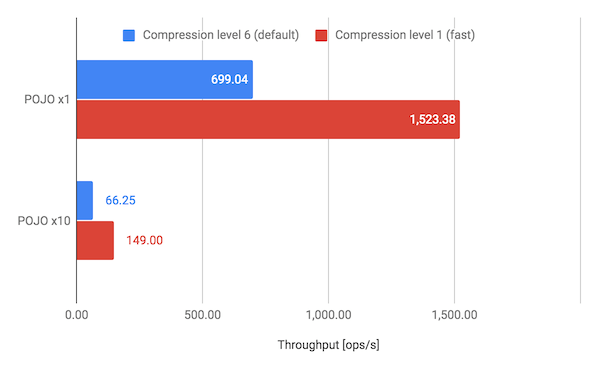
どちらのデータセットにおいても、圧縮レベルをデフォルトの 6 から 1 にすることでスループットを 2 倍以上に向上できています。ゆえに、高い圧縮性能が求められている状況でなければ、ひとまず圧縮レベルをデフォルトから緩める (可能ならば 1 にする) ことを試みてみるのがよいでしょう。
入出力バッファの調整・JSON シリアライズの最適化による影響を評価する
続いて、gzip 圧縮周りの入出力バッファの調整や JSON シリアライズを最適化した場合のスループットについて見ていきます。次のチャートにおける凡例の表記は、それぞれ以下を意味しています。
- Baseline: ベースライン実装 (圧縮レベルを 1 にする以外の調整はなし)
- InputBuffer (InBuf): 64KB のバッファを持つ
BufferedOutputStreamを Jackson とGZIPOutputStreamの間に挟む - OutputBuffer (OutBuf):
DeflaterOutputStreamの出力バッファを 64KB にする - Afterburner: Jackson の Afterburner モジュール (jackson-module-afterburner) を利用する
結果はこちら。
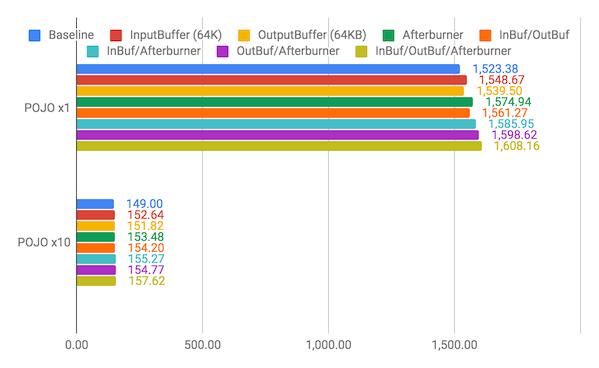
いずれのパフォーマンス改善の試みも、それを単体で適用することで (圧縮レベルと比較して僅かではあるけど) 1~3% 程度のスループットの向上が見られます。特に、Afterburner モジュールの利用は 3% 強のスループット向上という目立った改善が見られます。入出力バッファの調整よりも手軽にパフォーマンスを向上させられるという点においても、Afterburner を利用するメリットは大きいと言えるでしょう。
また、それぞれのパフォーマンス改善の試みを組み合わせて適用することで、加算的にスループットが伸びています。入出力バッファの調整と Afterburner モジュールすべてを組み合わせることで、5% の性能向上が達成できています。
なお今回は入出力バッファのサイズをどちらも 64KB に固定してベンチマークを測定していますが、実際にはシリアライズ対象である POJO (と、それをシリアライズした JSON) の特性、また同時並列に gzip 圧縮が行われうるスレッド数などの要素によって、スループット的に最適なバッファサイズはそれぞれ異なった値になることも考えられます。
まとめ
Jackson を使った POJO の JSON シリアライズと gzip 圧縮までの処理のスループットを高めるために、今回は圧縮レベルや入出力バッファサイズを調整したり、また Jackson の Afterburner モジュールを使ってシリアライズを最適化した結果のベンチマークを測定してみました。
結果としては、gzip の圧縮レベルを、圧縮性能を犠牲にしつつも速度重視に調整することがスループットを向上させるのに効果的である というありきたりな結論になるのですが、少しでもスループットを稼ぎたいという状況においては、Afterburner モジュールの利用や入出力バッファサイズの調整なども考慮に入れると良いかもしれません。
以下、3 行まとめ。
- まずは、許容できる圧縮性能まで圧縮レベルを下げて (1 に近づけて) みる
- Jackson の Afterburner モジュールは簡単に利用できるので、気軽に試してみる
- 入出力のバッファ調整は (改善幅は大きくないものの) 地味に効果があるので、限界までパフォーマンスを向上させたいのであれば調整をしてみる
-
HTTP レスポンスを gzip 圧縮するだけなら Nginx などのリバースプロキシ側にその処理を任せればいい話ではあるのですが、HTTP レスポンスのヘッダに gzip 圧縮後のサイズを
Content-Lengthヘッダに設定したい、という止むに止まれぬケースをここでは想定しています。 ↩ -
zlib には、これらの内部パラメータ 5 つのうち compress_func を除いた最初の 4 つを調整できる
deflateTune()関数が存在しますが、Java のクラスライブラリにはこれら内部パラメータを調整する機能は提供されていません。 ↩