

Guava の BloomFilter で文字列を効率よく捌きたい
(Google) Guava のブルームフィルタ実装 で String オブジェクトを効率よく扱う方法のメモです。
tl;dr
- Java のバージョン (Java 9 未満とそれ以降) や文字列に含まれる文字の種類によって、速度パフォーマンスが左右されるよ
- ISO-8859-1 に含まれる文字 (いわゆる半角英数字など) のみの文字列なら、
Funnels.stringFunnel(Charset)メソッドを用いて引数にStandardCharsets.UTF_8もしくはStandardCharsets.ISO_8859_1を指定するのが効率的だよ - ひらがな・カタカナなどが混じった (ISO-8859-1 以外の文字が含まれる) 文字列の場合は
Funnels.unencodedCharsFunnel()メソッドを使うといいよ
Guava のブルームフィルタ実装の使い方
Java における approximate membership query を実現するデータ構造の実用的な実装の一つに、Guava のブルームフィルタ実装が挙げられます。この Guava のブルームフィルタ実装は、例えば以下のように利用します。
import com.google.common.hash.*;
public class BloomFilterDemo {
public static void main(String[] args) {
// BloomFilter.create(Funnel<T>, int) などでインスタンスを生成する
BloomFilter<String> filter = BloomFilter.create(Funnels.unencodedCharsFunnel(), 10, 0.01);
// BloomFilter#put(T) でブルームフィルタに要素を追加する
filter.put("a");
filter.put("b");
filter.put("c");
// BloomFilter#mightContain(T) などで要素が存在するか否かを問い合わせる
System.out.println(filter.mightContain("a")); // => true
System.out.println(filter.mightContain("A")); // => false
}
}
ここで、文字列 (String オブジェクト) を取り扱う BloomFilter クラスのインスタンスを生成する場合に指定できる Funnel オブジェクトとして Funnels.stringFunnel(Charset) メソッドと Funnels.unencodedCharsFunnel() メソッドそれぞれが返す Funnel オブジェクトの二種類があるのですが、これらが速度パフォーマンス的にどのような違いがあるのかをベンチマーク計測しつつ評価してみることにします。
内部実装をちょっと理解する
さて具体的なベンチマークを測定する前に、Funnels.stringFunnel(Charset) / Funnels.unencodedCharsFunnel() メソッドそれぞれによって得られる Funnel オブジェクトの内部実装について少し理解を深めておきましょう。
まず Funnels.stringFunnel(Charset) メソッドについてですが、こちらは内部的には String オブジェクトを指定の Charset に従ってエンコードして byte 配列を生成し、それををブルームフィルタのハッシュ値計算に用いています。ゆえに、ハッシュ値の計算に要する時間以外に、byte 配列の生成や文字エンコーディングといった処理の時間が余計にかかることに留意する必要があります。
対して Funnels.unencodedCharsFunnel() メソッドは、String#charAt(int) で得られる char の値を逐次ハッシュ値計算に費やす 実装となっています。こちらはハッシュ値計算以外の余計な処理が発生することはないものの、ハッシュ値計算の内部状態を 1 つの char ごとに都度更新することになるため、byte 配列から一気にハッシュ値を計算するのと比較して諸々のオーバーヘッドが嵩む可能性があります。
Java 9 以降の文字列表現の影響
話は Guava のブルームフィルタから逸れますが、Java 9 から 文字列の内部表現が char 配列から byte 配列に変更された ことは記憶に新しいことかと思います。これにより、ISO-8859-1 の文字のみで表現可能な文字列の場合は 1 文字を 1 バイトで表現されるようになりました。
この文字列の内部表現の変更は Charset を指定したエンコーディング処理にかなりの影響を及ぼしており、例えば ISO-8859-1 のみで構成される文字列に対する UTF-8 のエンコーディング処理は、byte 配列のコピーのみ で済ませられるようになっています。これは特に Funnels.stringFunnel(Charset) を用いる場合にパフォーマンスへの影響が生じる可能性が高いため、後述するベンチマークもこれを考慮した構成にしています。
ベンチマーク
ベンチマーク計測に利用したコードは こちら です。
測定条件
今回のベンチマークは以下の条件で測定しています。
- Java バージョン
- Java 8 と Java 11
- 文字列の種類
- 数字のみの文字列と、ひらがなと英字混在の文字列
- 文字列の個数
- 16,384 個
- 文字列長
- 20 文字
Funnels.stringFunnel()の引数に与えるCharsetStandardCharsets.ISO_8859_1,StandardCharsets.UTF_8,StandardCharsets.UTF_16の 3 種類- ひらがなを含む文字列に対して
StandardCharsets.ISO_8859_1の文字エンコーディングを適用するのは適切ではないため、ベンチマークの測定結果からは除外
測定結果
文字列の種類ごとにベンチマーク測定結果を見ていきます。まずは数字のみで構成された文字列の結果から。
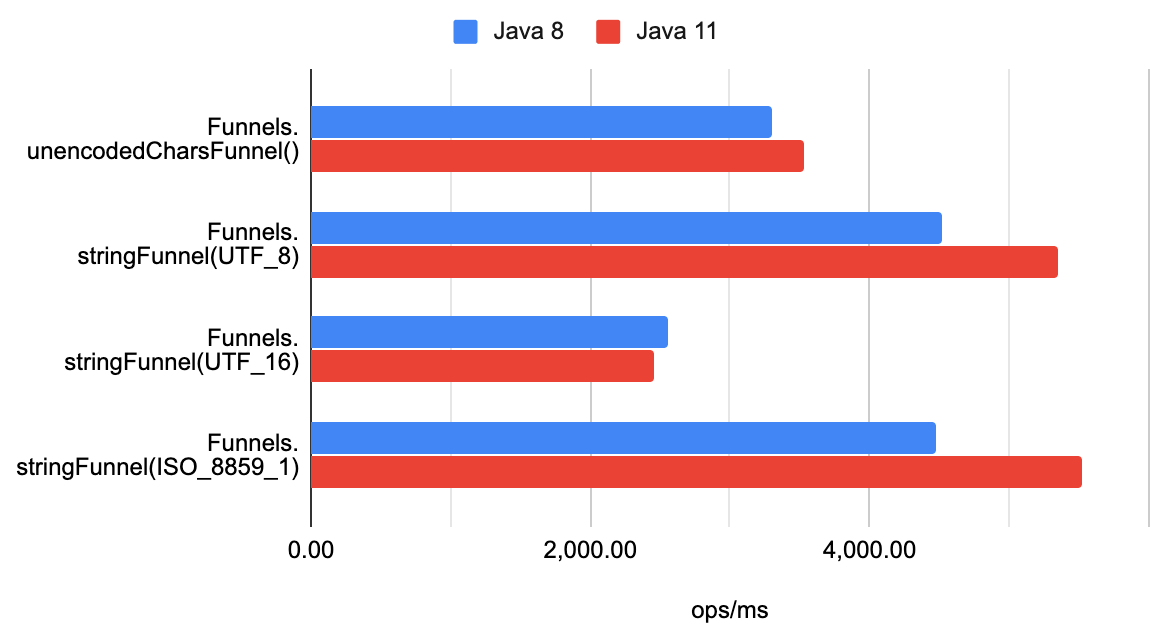
Java のバージョンによって一部大きな差が生じている Funnel が存在しますが、測定結果の傾向としては、
- 👍
Funnels.stringFunnel(ISO_8859_1)もしくはFunnels.stringFunnel(UTF_8) Funnels.unencodedCharsFunnel()Funnels.stringFunnel(UTF_16)
となりました。つまり、ISO-8859-1 の文字のみで表現可能な文字列を扱うのであれば、byte 配列の生成コストや文字エンコーディングの変換コストを払ってでも Funnels.stringFunnel() を使うのがベストと言えるでしょう。
また、Java 11 と Java 8 とで Funnels.stringFunnel(ISO_8859_1) などの速度パフォーマンスに大きな差が生じているのは前述したとおり、JEP 254 による文字列の内部表現の変化の影響によるものと見られます。
続いて、ひらがなと英字が混在する文字列の結果です。
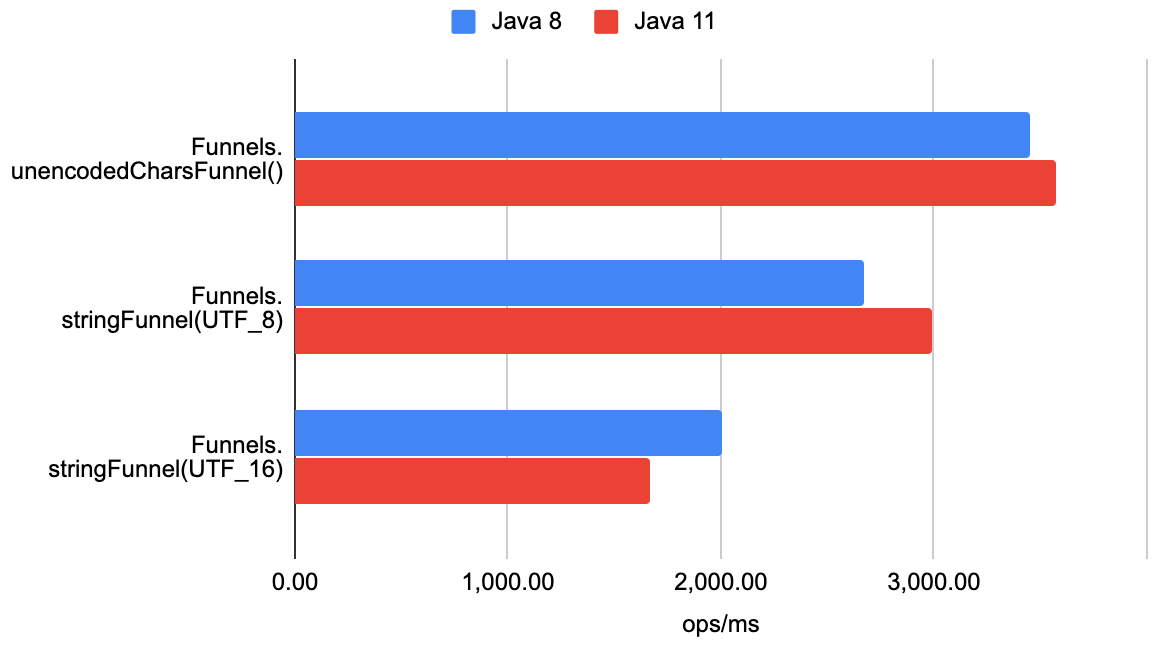
こちらは先ほどとは異なり、
- 👍
Funnels.unencodedCharsFunnel() Funnels.stringFunnel(UTF_8)- [Worst]
Funnels.stringFunnel(UTF_16)
という傾向になりました。これは文字エンコーディングにかかる処理の影響が顕著にあらわれていると見てよいでしょう。
まとめ
Java のバージョンによって速度パフォーマンスの差はあれど、
- 半角英数字など ISO-8859-1 の文字のみで表現される文字列については
Funnels.stringFunnel(ISO-8859-1)を使うべき - 一方でひらがななどが混じる場合は
Funnels.unencodedCharsFunnel()を使うべき
と言えるでしょう。