

Production-ready な Xor filter の Java 実装を作った
ブルームフィルタの代替手段として利用できうる Xor filter を Java で実装して アーティファクトを Bintray で公開しました、というお話です。
はじめに
Xor filter は一ヶ月ぐらい前に arxiv.org でプレプリントが公開された ばかりのまだまだ新しいデータ構造で、ブルームフィルタ と同様に false positive が発生しうる approximate membership query を提供します。その特徴は論文や 共著者のブログエントリ でも語られているように、ブルームフィルタと比較して、
- Approximate membership query が速い
- メモリフットプリントが小さい
この二点が挙げられます。
なお Xor filter の具体的な実装は著者らによって、C/C++, Go, Java のリファレンス実装が提供されています。このうち Java 実装については、現時点では long 以外の要素 (String オブジェクトなど) を扱えない、どこの Maven リポジトリにもアーティファクトが存在しないなどの理由でプロダクション利用しづらい問題があるため、 (Google) Guava のブルームフィルタ実装 のインタフェースを参考に改めて Java 実装したものをパッケージし、そのアーティファクト me.k11i:xor-filter を Bintray (jcenter) で公開 することにしました。
ソースコードは komiya-atsushi/xor-filter で公開しています。
利用方法
依存ライブラリ
例えば Gradle であれば、以下のように Maven リポジトリおよび依存ライブラリを記述します。
repositories {
// 以下は jcenter() で置き換えてもよい
mavenCentral()
maven {
url "https://dl.bintray.com/komiya-atsushi/maven"
}
}
dependencies {
implementation 'com.google.guava:guava:28.2-jre'
implementation 'me.k11i:xor-filter:0.1.1'
}
なお現状の me.k11i:xor-filter は、ハッシュ関数そのものやオブジェクトのハッシュ値算出周りの実装を Guava に頼りきっています。そのため、com.google.guava:guava もあわせて依存ライブラリに追加する必要があります。
インタフェース
Guava のブルームフィルタ実装では、オブジェクトのハッシュ値計算に Funnel インタフェース のオブジェクトを利用していますが、この Xor filter の実装でもその Funnel インタフェースをそのまま採用することにします。具体的な Funnel のオブジェクトは、Funnels クラス が提供するものを利用することとします。
例えば要素として文字列を扱う Xor filter を新たに作成したいのであれば、以下のように Funnels.stringFunnel(Charset) などを呼び出して Funnel オブジェクトを用意し、それを XorFilter.build() メソッドに引数で渡すようにします。
XorFilter<String> filter = XorFilter.build(
// Xor filter で取り扱うオブジェクトに適した Funnel オブジェクトを指定する
Funnels.stringFunnel(StandardCharsets.UTF_8),
// Xor filter に追加したい要素を、XorFilter オブジェクトを作成する際に指定する必要がある
Arrays.asList("foo", "bar", "baz"),
// 具体的な実装を指定する
XorFilter.Strategy.MURMUR128_XOR8)
現時点では、Xor filter の具体的な実装として以下の二つを提供しています (Xor+ filter はまだ実装していません)。
XorFilter.Strategy.MURMUR128_XOR8- ハッシュ関数として 128 ビット MurmurHash3 を利用する
- Fingerprint を 8 ビットで表現する
XorFilter.Strategy.MURMUR128_XOR16- ハッシュ関数として 128 ビット MurmurHash3 を利用する
- Fingerprint を 16 ビットで表現する
MURMUR128_XOR8 は、フィルタに含まれる要素 1 つあたり 9.84 ビット消費し、false positive が生じる確率は約 0.39% 程度となります。一方で MURMUR128_XOR16 は MURMUR128_XOR8 と比べて約 2 倍となる 19.68 ビットを 1 要素あたり必要としますが、false positive の確率は 0.002% 弱となります。
肝心の Approximate membership query は、こちらも Guava のブルームフィルタ実装と同じく Xor Filter#mightContain(T) もしくは Predicate#test(T) のメソッド呼び出しで実現します。
// Guava と同じ名前のメソッドを提供している
filter.mightContain("foo");
// java.util.function.Predicate インタフェースを実装しているので、Predicate#test(T) も利用できる
filter.test("hoge");
また構築済みの XorFilter オブジェクトをなにがしかのストレージに永続化したり、他の Java プロセスで再利用しやすくすることを目的に、XorFilter オブジェクトを byte 配列で表現する、もしくは byte 配列表現から XorFilter を復元するための仕組みも備えています。
// byte 配列にシリアライズする
byte[] serialized;
try (ByteArrayOutputStream out = new ByteArrayOutputStream()) {
filter.writeTo(out);
serialized = out.toByteArray();
}
// byte 配列から元の XorFilter オブジェクトを復元する
XorFilter<String> deserialized = XorFilter.readFrom(
new ByteArrayInputStream(serialized),
// Funnel オブジェクトはシリアライズ結果に含まれないため、復元時に明示的な指定が必要となる
Funnels.stringFunnel(StandardCharsets.UTF_8));
Guava のブルームフィルタ実装との比較
ブルームフィルタに限らず、approximate membership query をサポートする各種データ構造との性能比較は論文中でもされています。ここでは Guava のブルームフィルタ実装を対象に、速度性能とメモリフットプリントを測定して比較してみます。
なお比較用のブルームフィルタは、Xor filter の 8 ビット実装、16 ビット実装との比較を容易にするため、false positive probability に 0.389% と 0.002% をそれぞれ設定した二つを用意します。
速度性能
速度性能は、JMH を利用したベンチマークで測定します (コードは こちら)。フィルタで扱う要素として、Long オブジェクトと String オブジェクトの 2 種類をそれぞれ試してみます。
まずは Long オブジェクトでの結果を見ていきましょう。
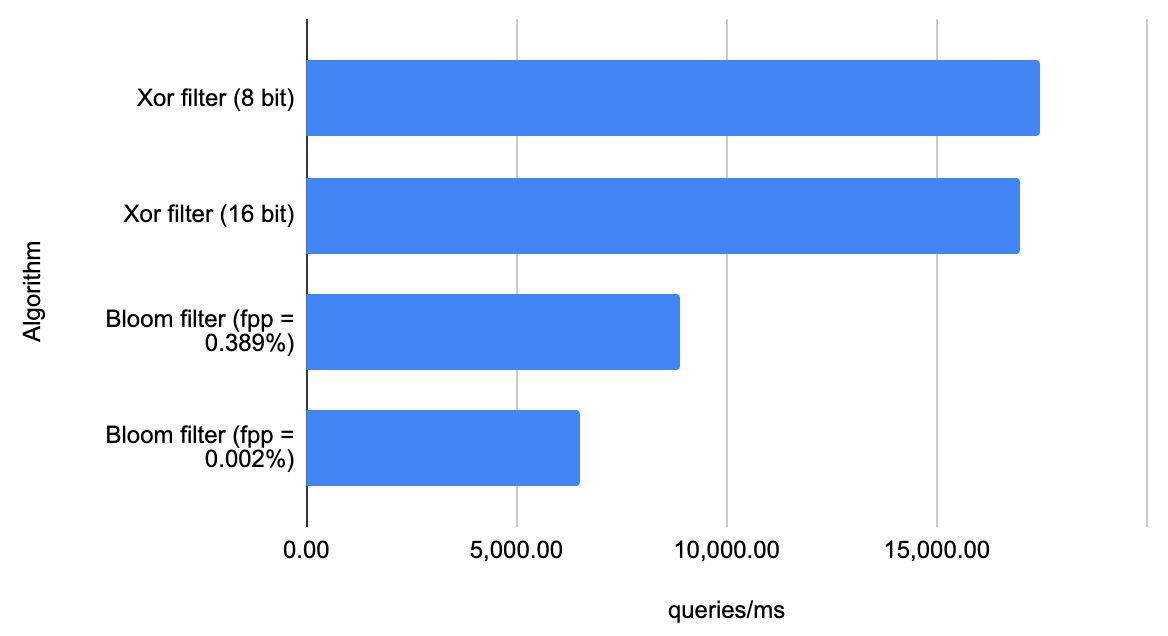
ご覧のとおり、スループット (クエリ/ミリ秒) で見ると、同程度の false positive probability を実現する Guava のブルームフィルタ実装とそれぞれ比較してダブルスコア以上の性能が出ています。
続いて String オブジェクトでの結果を見てみます。
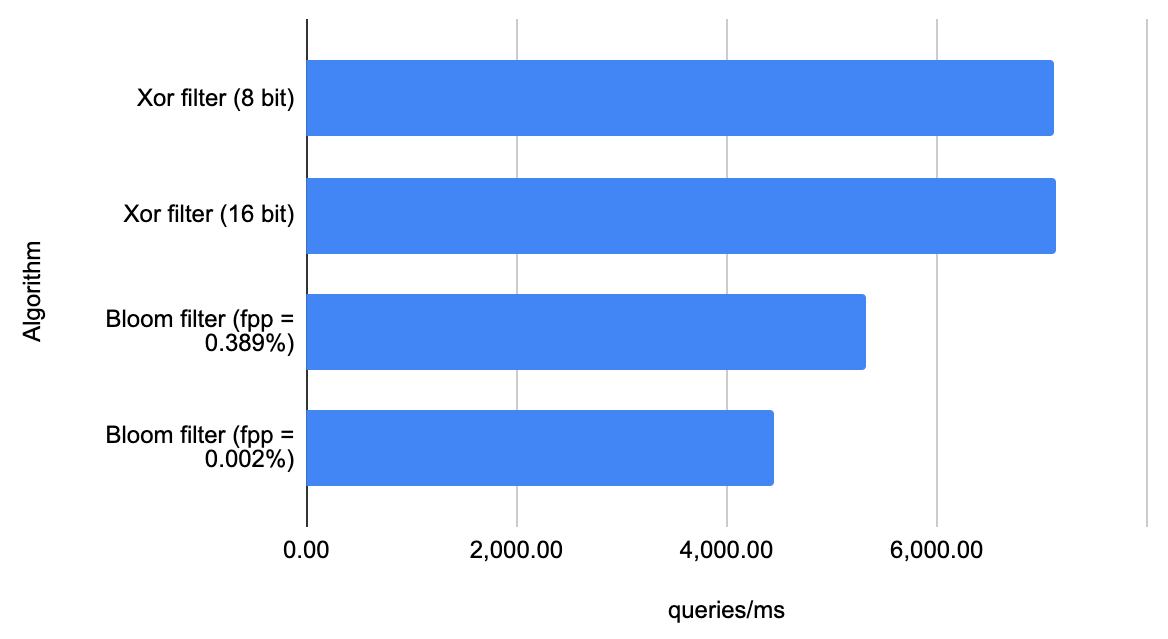
String オブジェクトはハッシュ値計算にかかるコストが高めであるため、Long オブジェクトのときと比較してフィルタ自体の性能差が結果に表れにくいのですが、それでも 30 ~ 60% ぐらいの速度向上が見られます。
メモリフットプリント
続いてメモリフットプリントを見ていきます。
なお実際のヒープ使用量を計測するのは何かと面倒なので、ここではフィルタをシリアライズして byte 配列表現したときのバイト数をもってメモリフットプリントを推定することにします。
測定に利用したコードは こちら で、結果は以下のとおりです。
| Algorithm | シリアライズ結果のバイト数 | 要素あたりのビット数 |
|---|---|---|
| Bloom filter (fpp = 0.389%) | 144,390 | 11.551 |
| Bloom filter (fpp = 0.002%) | 281,510 | 22.521 |
| Xor filter (8 bit) | 123,042 | 9.843 |
| Xor filter (16 bit) | 246,075 | 19.686 |
同等の false positive probability を実現するブルームフィルタと比較して、その 85 ~ 87% 程度のメモリフットプリントを達成できています。
制限・制約
このように Xor filter は、ブルームフィルタの具体的な実装と比較して速度やメモリフットプリントの面で優れた性能を有します。しかし、この Xor filter でブルームフィルタのユースケースをすべて置き換えられるかというとそうでもなく、Xor filter では実現できないこともまた存在します。
フィルタ構築後の変更操作・オンライン構築
Xor filter は論文にもあるように イミュータブル なデータ構造となるため、フィルタ構築を終えた後は新たな要素を挿入できなくなります。同様に、オンライン・逐次処理による Xor filter の構築も容易ではありません (フィルタに追加すべき要素が出揃ってから初めて、フィルタの構築に取りかかれるため)。
False positive probability の調整
Guava のブルームフィルタ実装には、フィルタに挿入される要素数がある程度推定できれば false positive probability の調整が容易である という特性があります。
一方で、Xor filter は fingerprint の表現に用いるビット数によって false positive probability が決定してしまうため、メモリフットプリントと false positive probability のトレードオフを調整できません。
まとめ
ブルームフィルタとは異なり Xor filter には一部に機能的な制約があるものの、フィルタの構築とフィルタの利用 (approximate membership query) を完全に分離した使い方をするのであれば、Xor filter は最適な手段の一つと言えるかもしれません。