

一週間で構築できる! お手軽データウェアハウス
Legalscape (リーガルスケープ) アドベントカレンダー 2021 の 12/16 (木) のエントリです。
本日のエントリは、突貫工事的に一週間程度1で構築したデータウェアハウスについてお送りいたします。
データウェアハウス構築前夜
2021 年 6 月に予定をしている Legalscape 正式版リリースが刻々と迫り、みなが慌ただしく仕事をしている 5 月下旬、ビジネス上の様々な理由からユーザのアクティビティログを保持して分析・集計するデータ基盤、すなわちデータウェアハウスが必要になりました。
Legalscape ではそれまで、プロダクト上でのユーザの行動に伴って発生するアクティビティログはすべて (書籍の全文検索に用いているものと同じ) Elasticsearch クラスタにインデックスしていました。アクティビティログを利用する際は、このインデックスに対して Kibana を通じてクエリ (KQL) を投げ必要なアクティビティログを絞り込んで抽出したのちに、Python スクリプトでログを加工したり Excel で集計するなどしていました。
しかしながら、エンジニアメンバーだけでなくビジネスサイドのメンバーがアクティビティログに対してアドホックな分析をすることを考えると、Kibana を活用するよりも、今を生きるビジネスパーソン的に潰しが利く――もはや現代の必須スキルと言っても過言ではない―― SQL でクエリできること2が望ましいと考えられました。
また BI ダッシュボードから参照されるデータソースとして考えたときに、負荷が予測しづらいクエリが Elasticsearch クラスタに投げられるのは避けたいという思惑もあり、正式版リリースまで一週間に満たない短期間ではありましたが新たにデータウェアハウスを構築する決断をしました。
Legalscape のデータウェアハウスの概要
実際どのようにデータウェアハウスを構築したのか? については後述するとして、現時点でのデータウェアハウスとその周辺のシステム構成を以下の図に示します。
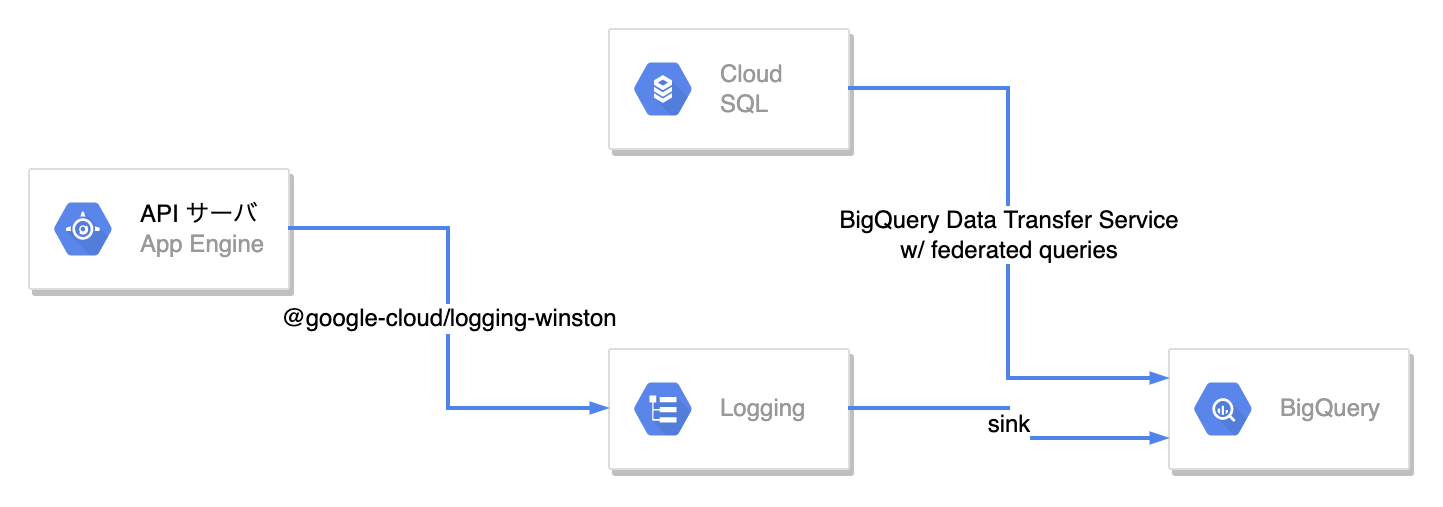
ご覧のとおり、Legalscape では BigQuery を用いてデータウェアハウスを構築しています。Google Cloud Platform を利用しているのであれば、この BigQuery は当然の選択と言えますね。Fully managed なので面倒な運用の手間がほとんどなく、かつデータの規模が小規模であれば非常に安価に利用を始められるのが何よりの利点として挙げられるでしょう。
App Engine 上の API サーバからは、フロントエンドから受信したアクティビティログを JSON のフォーマットで Cloud Logging に出力しています。Legalscape では API サーバのロギングライブラリとして Winston を採用しており、Google が公式に提供している Winston 向けのインテグレーションライブラリ @google-cloud/logging-winston と組み合わせて利用しています。
そしてこの Cloud Logging からはシンクを用いて、 アクティビティログを BigQuery に準リアルタイムでエクスポートしています。
それとは別に、Cloud SQL (MySQL) 上に存在するマスタテーブルを Cloud SQL 連携クエリ の機能を用いて BigQuery から参照可能な状態にしています。加えて BigQuery Data Transfer Service を利用して Cloud SQL のマスタテーブルのデータを BigQuery に日次でインポートしつつ、履歴を保持するようにしています。
Terraform による構築
さてこの BigQuery を中心としたデータウェアハウスですが、構築には 12/9 のエントリでご紹介した Terraform を大いに活用しています。具体的に利用しているリソースは以下のとおりです。
- google_bigquery_dataset リソース
- BigQuery のデータセットの定義
- google_bigquery_table リソース
- ログテーブルを除く BigQuery のテーブルの定義
- google_logging_project_sink リソース
- Cloud Logging シンクの定義
- google_bigquery_connection リソース
- Cloud SQL 連携クエリを利用する際に必要となる BigQuery 接続サービスの設定
- google_bigquery_data_transfer_config リソース
- Cloud SQL から BigQuery にマスタテーブルをインポートするスケジュールクエリの定義
また Terraform コンフィギュレーションの具体例は以下になります。
locals {
project_id = "GCP プロジェクトの ID をここに指定する"
# Cloud Logging に出力されるログ
log_names = [
"foo_log",
"bar_log",
]
# Cloud SQL 上のテーブル
tables = [
"foo_table",
"bar_table",
]
}
resource "google_bigquery_dataset" "this" {
dataset_id = "データセットIDをここに指定する"
location = "asia-northeast1"
}
# ログテーブルは google_bigquery_table リソースで明示的に出力先テーブルを定義する必要がなく、
# このシンクを定義をするだけで十分である
resource "google_logging_project_sink" "this" {
for_each = toset(local.log_names)
name = each.key
destination = "bigquery.googleapis.com/projects/${local.project_id}/datasets/${google_bigquery_dataset.this.dataset_id}"
filter = "logName=\"projects/${local.project_id}/logs/${each.key}\""
unique_writer_identity = true
bigquery_options {
use_partitioned_tables = true
}
}
# シンクを作成したときに同時に作成されるサービスアカウントに、
# BigQuery にデータを追加することのできる権限を明示的に付与する必要がある
resource "google_project_iam_member" "this" {
for_each = toset(local.log_names)
role = "roles/bigquery.dataEditor"
member = google_logging_project_sink.this[each.key].writer_identity
}
# BigQuery から Cloud SQL に連携クエリ (federated queries) を投げるための接続設定
resource "google_bigquery_connection" "this" {
provider = google-beta
connection_id = "cloudsql-connection"
friendly_name = "Cloud SQL connection"
location = "asia-northeast1"
cloud_sql {
database = "接続先の MySQL のデータベース名"
instance_id = "Cloud SQL のインスタンス ID"
type = "MYSQL"
credential {
username = "MySQL 接続ユーザ名"
password = "接続パスワード"
}
}
}
data "google_project" "project" {
}
# BigQuery Data Transfer Service が利用するサービスアカウントに適切な権限を付与する必要がある
resource "google_project_iam_member" "permissions" {
role = "roles/iam.serviceAccountShortTermTokenMinter"
member = "serviceAccount:service-${data.google_project.project.number}@gcp-sa-bigquerydatatransfer.iam.gserviceaccount.com"
}
# Cloud SQL からインポートしたデータを入れるテーブルを定義する
resource "google_bigquery_table" "this" {
for_each = toset(local.tables)
dataset_id = google_bigquery_dataset.this.dataset_id
table_id = each.key
# Terraform コンフィギュレーションの可読性を維持するために、
# テーブルの具体的なカラム定義はコンフィギュレーションに直接記述せずに
# 別ファイルに記述する
schema = "schemas/${each.key}.json"
time_partitioning {
type = "DAY"
}
}
# 実際に Cloud SQL からテーブルのデータをインポートするスケジュールクエリを定義する
resource "google_bigquery_data_transfer_config" "this" {
for_each = toset(local.tables)
depends_on = [google_bigquery_table.this[each.key]]
display_name = "load-${each.key}"
location = "asia-northeast1"
data_source_id = "scheduled_query"
# 毎日 0:05 JST にインポートクエリを実行する
schedule = "every day 15:05"
destination_dataset_id = google_bigquery_dataset.this.dataset_id
params = {
# パーティションの日付が JST になるように調整している
destination_table_name_template = "${each.key}_history$${run_time+9h|\"%Y%m%d\"}"
write_disposition = "WRITE_APPEND"
# テーブル定義同様にインポートクエリは別ファイルに記述する
query = "queries/${each.key}.json"
}
}
上記コンフィギュレーションはかなり行数があって読みにくく感じる方もいらっしゃるかと思いますが3、fluentd の設定ファイルや長大なログ取り込みクエリ、アプリケーションコードなどをほとんど書くこともなく、これだけの記述で十分に活用できるデータウェアハウスが構築できるわけでして、随分とよい時代になったなあ… という気持ちでいっぱいです。
また上記のコンフィギュレーションのコメントにあるように、Cloud SQL からインポートしたデータを入れるためのテーブル定義とその具体的なインポートクエリはコンフィギュレーションには記述せず、以下のような内容で別ファイルに記述しています。
// テーブル定義ファイルの例
[
{
"name": "id",
"type": "INT64",
"mode": "NULLABLE"
},
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "created_at",
"type": "DATETIME",
"mode": "NULLABLE"
},
{
"name": "updated_at",
"type": "DATETIME",
"mode": "NULLABLE"
},
{
"name": "deleted_at",
"type": "DATETIME",
"mode": "NULLABLE"
}
]
-- インポートクエリの例
SELECT
cast(id AS INT64) AS id,
name,
created_at,
updated_at,
deleted_at
FROM
EXTERNAL_QUERY('cloudsql-connection', 'SELECT * FROM database_name.foo_table')
現状の構成の課題
このデータウェアハウス構築から半年以上が経過し、いまのところ大きな不満はないものの、まだやり残していることが多々あります。
Elasticsearch に入っている過去ログのインポート
当初は Elasticsearch 上の過去ログについては参照することもそう多くないだろうし割り切って Kibana だけで扱えればいいかな… と考えていました。しかし実際には過去のログ含めて分析をしたいというケースがそれなりに発生しており、分析プラットフォームを統一するためにも過去ログを BigQuery に取り込む必要があると考えています。
ログテーブルの細分化
現時点ではアクティビティログは種類ごとに分類せずに一つのテーブルにすべて入れています。これを種類ごとに別テーブルに分離して BigQuery に取り込むことで、スキーマ不一致の問題のリスク低減を図ります。
データパイプラインの整備
日次や月次など定期的に実行したいクエリが複数あった場合、依存関係を考慮してクエリを順に実行したいのですが、BigQuery Data Transfer Service で利用できるスケジュールクエリではそのような依存関係の定義はいまのところできないと認識しています。そこで Apache Airflow のフルマネージドサービスである Cloud Composer を導入し、依存関係を考慮したスケジュールクエリ実行環境を整備しようと画策しています。
BI ダッシュボードの整備
データウェアハウスを早々に整備したことで分析に必要なデータは続々と蓄積されてはいますが、定常的に把握したい KPI をすぐに確認できる BI ダッシュボードの整備がまだ進んでいません。GCP 上に作られたデータウェアハウスとの親和性を考えるとデータポータルもしくは Looker が有力な選択肢であると考えていて、まずは Looker のトライアルを早々に始める予定でいます。
おわりに
このエントリでは Legalscape のデータウェアハウスの概要および構築方法についてご紹介しました。
最後のセクションで書いたように弊社のデータウェアハウスはまだ発展途上であり、これを少しでも完成形に近づけるためにはデータエンジニアリングに強いソフトウェアエンジニアの協力が必要不可欠です。
現時点では「データエンジニア」という明確なタイトルでのポジションの募集はありませんが、「ソフトウェアエンジニア」のポジションで担当できる領域ではありますので、ご興味ある方は以下の採用情報の案内からご応募、もしくはカジュアル面談をご利用くださいませ!
最後までお読みいただきありがとうございました!
-
厳密には、ユーザのアクティビティログを Cloud Logging 経由で BigQuery に入れてクエリ可能にする最低限のところまでを一週間かけずに達成したわけで、Cloud SQL からのマスタテーブルのインポートはまた別途時間を確保して対応しています。 ↩
-
Elasticsearch でも platinum プランを購入していれば、JDBC driver を使って SQL でクエリ できるようです。 ↩
-
実際に弊社で管理しているコンフィギュレーションはモジュール化していたりファイルを分割して管理しているので、これよりもだいぶ読みやすくなっています。 ↩