

「#JJUG ナイトセミナー ビール片手に LT 大会」で Fork/Join フレームワークのお話をしました
5 分で話しきれずあえなく時間切れの憂き目にあった資料の供養を兼ねたエントリです。
Fork/Join フレームワークのデザインパターン・アンチパターンのパフォーマンス影響を把握したい
先日の Fork/Join Parallelism in the Wild の論文を読んだメモ では、Fork/Join フレームワークを利用する上でのベストプラクティス、デザインパターン、そしてアンチパターンについて説明しました。今回は、速度パフォーマンスに影響のあるデザインパターン・アンチパターンの一部について、実際に例題を用意してベンチマークを計測し、どれくらいパフォーマンスに影響があるかを調べたメモになります。
発表資料は こちら です。またベンチマーク測定に使ったコードは こちらの GitHub リポジトリ で公開しています。
デザインパターンの Sequential Cutoff をベンチマーク計測する
Sequential Cutoff は、サブタスクへの分割を打ち止めにするしきい値 (cutoff) を適宜設定して並列性とオーバーヘッドのトレードオフのバランスをとることを目的としたデザインパターンです。
ここで、Fork/Join フレームワークを利用した単純なマージソート実装 を例題に、長さ 30 万の double 配列をソートする処理に対してしきい値を 10 から 100,000 まで 10 倍刻みに変化させたときの速度パフォーマンスを測定した結果が以下になります (MergeSort 右横のカッコ内の数値がしきい値を表します)。
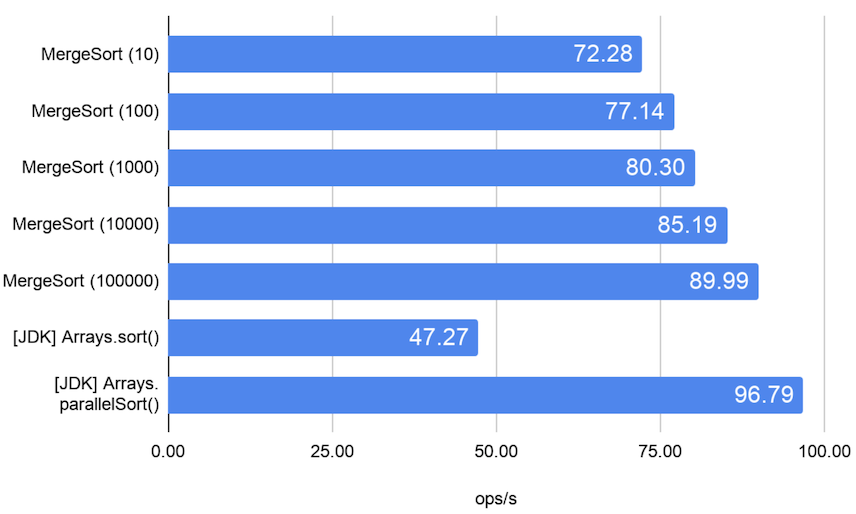
このベンチマークでは、しきい値が大きい、すなわちタスクの粒度が大きいほどパフォーマンス (1 秒あたりの処理回数) が良いという結果が得られたものの、際限なくしきい値を大きくすると今度は並列性が大きく損なわれることになるため、慎重なしきい値の見極めが必要になることには変わりありません。
2 つのアンチパターンをベンチマーク計測する
続いて、Heavyweight Merging と Inappropriate Resource Sharing の 2 つのアンチパターンについて速度パフォーマンスを測定します。
このベンチマークでは、$[0, 1)$ の区間から一様にサンプリングした浮動小数点の値を長さ 50 万の double 配列で保持しておき、この配列から $k=0.5$ 以上の値を抽出して List<Double> に詰めて列挙する、という例題を扱うことにします。
Heavyweight Merging のアンチパターンでは、サブタスクは List<Double> で結果を表すようにし、親タスクにおけるマージ処理は単に List#addAll(Collection) メソッドで一方のサブタスクの結果にもう一方のサブタスクの結果を追加するような 実装 としています。一方で Inappropriate Resource Sharing のアンチパターンでは、Collections.synchronizedList() で包まれた ArrayList のオブジェクト一つをタスク間で共有し、そのリストに各々のタスクから任意のタイミングで List#add() するような 実装 にしています。
また比較対象としての ベースライン実装 では、末端のサブタスクによって抽出された値を List<Double> で表現しつつ、Fork/Join フレームワークでの並列処理を終えた後に一括してマージする実装としています。
以下がベンチマークの測定結果です。
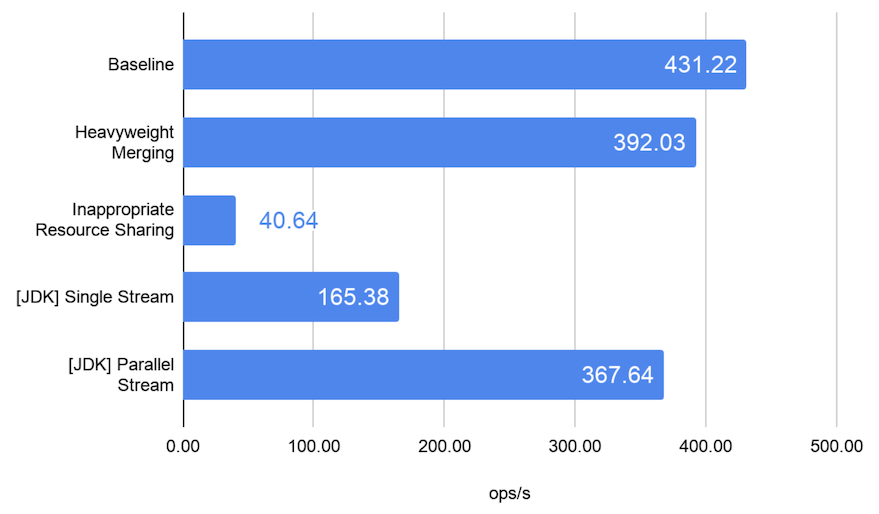
Inappropriate Resource Sharing のアンチパターンは、ベースラインと比較して 1/10 以下まで速度パフォーマンスが劣化してしまっています。これはシングルスレッドで処理した場合よりも悪い結果となります。このアンチパターンにおいては、今回は Collections.synchronizedList() を利用したことがそのパフォーマンス劣化の原因になるわけですが、これに限らず同期を要する類の処理は、Fork/Join フレームワークを利用した並列処理から極力排除することが望ましいと言えるでしょう。
Heavyweight Merging もベースラインに対して 10% ほどの速度低下が見られます。このアンチパターンを回避するためには、例えば今回のベースラインのように、多少手の込んだ実装が要求されるため、場合によってはこの程度のパフォーマンス劣化は許容するといった判断もあり得るかもしれません。
なお参考までに、Fork/Join フレームワークを直接使わずに Stream#parallel() で並列処理した場合のパフォーマンスも同時に測定しています。こちらは意外なことにベースラインの 85% 程度の速度性能しか出ておらず、Java の標準的な機能だからといって必ずしも高いパフォーマンスが保証されるというわけではないことがわかります。
まとめ
論文で紹介されていたデザインパターン・アンチパターンの一部についてベンチマークを測定し、そのパフォーマンスに与える影響を確認しました。特にアンチパターンにおいては速度パフォーマンスに甚大な影響を与えるものもあるため、Fork/Join フレームワークを用いて処理の並列化を試みる場合はアンチパターンに陥らないように注意を払う必要がありそうです。
また、処理内容によっては Stream#parallel() で並列処理するよりも Fork/Join フレームワークを直接使って並列処理した方がパフォーマンスが向上するケースもあるため、特に速度を要求される処理を実装する必要がある場合は Fork/Join フレームワークの利用を積極的に検討してみるのもありでしょう。